Introducing Foundation AI’s Testing Hub for Cybersecurity

Announcing Foundation AI’s Cybersecurity Evaluation Package
We’re excited to introduce our new Foundation AI Testing Hub (FAITH) Cybersecurity Evaluation package, a powerful tool designed to streamline and standardize the evaluation of large language models (LLMs) for cybersecurity contexts. This package consolidates existing open-source benchmark datasets into a single, cohesive tool, offering an easy-to-use and extensible framework for assessing the knowledge and aptitude of LLMs. Most notably, we plan to open-source this tool at the end of July, making it freely accessible to the broader community.
Key Features of FAITH
- A Comprehensive Benchmarking Framework The package consolidates a variety of open-source benchmarks, enabling users to compare models across a spectrum of cybersecurity tasks. It currently supports two primary benchmark categories: Multiple-Choice Question Answering (MCQA): Models select the best answer from a set of predefined options. Performance is evaluated using accuracy. Short-Answer Question (SAQ) Answering: Models generate free-form responses, which are scored using benchmark-specific metrics.
- Three-Stage Evaluation Process: To promote clarity and flexibility, the evaluation process is organized into three distinct stages: LLM Querying: Direct interaction with the model to generate predictions for each question in the benchmark. Metric Evaluation: Scoring the generated responses against ground-truth labels using benchmark-specific metrics. Metric Summarization: Aggregating and summarizing the results to provide actionable insights.
This modular design allows users to run each stage independently, making the framework easier to debug, customize, and extend for diverse evaluation needs.
- Support for Diverse Model Modes: The package is built to evaluate a range of model architectures and capabilities, including: Base Models: Foundational models trained for next-token prediction, but without instruction fine-tuning (IFT). These are typically evaluated using multi-shot prompting. Chat Models: IFT Models optimized for conversational AI, such as ChatGPT-like systems. Reasoning Models: Advanced IFT models built for tasks requiring logical inference and step-by-step problem-solving.
Each model type can be evaluated using customizable configurations, providing flexibility to suit different use cases.
- Extensibility to New Benchmarks Adding new benchmarks to the package is straightforward, thanks to its modular architecture and use of simple YAML configurations. This flexibility makes the tool especially useful for researchers looking to evaluate custom datasets or introduce new task formats with minimal overhead.
- Robustness via Unit Testing: To ensure reliability and correctness, the package includes comprehensive unit tests covering all major components. This testing framework helps guarantee the accuracy of evaluations and the overall robustness of the system.
Core LLM Infrastructure
The FAITH package is built on proven, high-performance libraries and frameworks to ensure scalability, efficiency, and ease of integration:
- vLLM and Llama.cpp: These frameworks handle fast, efficient querying for LLMs, with scalability across diverse GPU architectures.
- External APIs: The package supports integration with external inference APIs, allowing seamless integration with a variety of popular AI services to evaluate closed source models.
By leveraging these technologies, the package is well-equipped to support even the most demanding evaluation scenarios.
Supported Benchmarks
We’ve integrated a diverse set of open-source benchmarks to cover a range of cybersecurity evaluation needs. Currently, the package supports:
- CTIBench: Evaluates LLM performance in cyber threat intelligence (CTI) across five distinct tasks.
- CyberMetric: A retrieval-augmented benchmark designed to assess LLMs on cybersecurity-specific knowledge.
- MMLU: A general-purpose benchmark to evaluate the ability of AI models to perform a wide range of tasks across various subjects including cybersecurity.
- SecBench: A multi-dimensional benchmark for LLMs in cybersecurity.
- SecEval: Focuses on evaluating the cybersecurity knowledge embedded in foundation models.
In addition, we’ve developed our own custom benchmarks to extend the package’s coverage to new and emerging cybersecurity challenges, ensuring relevance to current threat landscapes.
Model Comparisons with FAITH
We utilized FAITH evaluations to conduct a comprehensive suite of tests evaluating the performance of our Foundation-Sec-8B base model against leading models in the industry, including Llama-3.1-8B, WhiteRabbit-v2-8B, Primus-Seed-8B, and GPT-4o-mini. FAITH enabled comprehensive and consistent measurements over multiple cybersecurity benchmarks. The results provided valuable insights into our model’s capabilities, particularly on security tasks like Root-Cause Mapping (RCM). The full benchmarking analysis, along with detailed findings, is documented in our Llama-3.1-FoundationAI-SecurityLLM-Base-8B Technical Report, but below we reproduce its key findings.
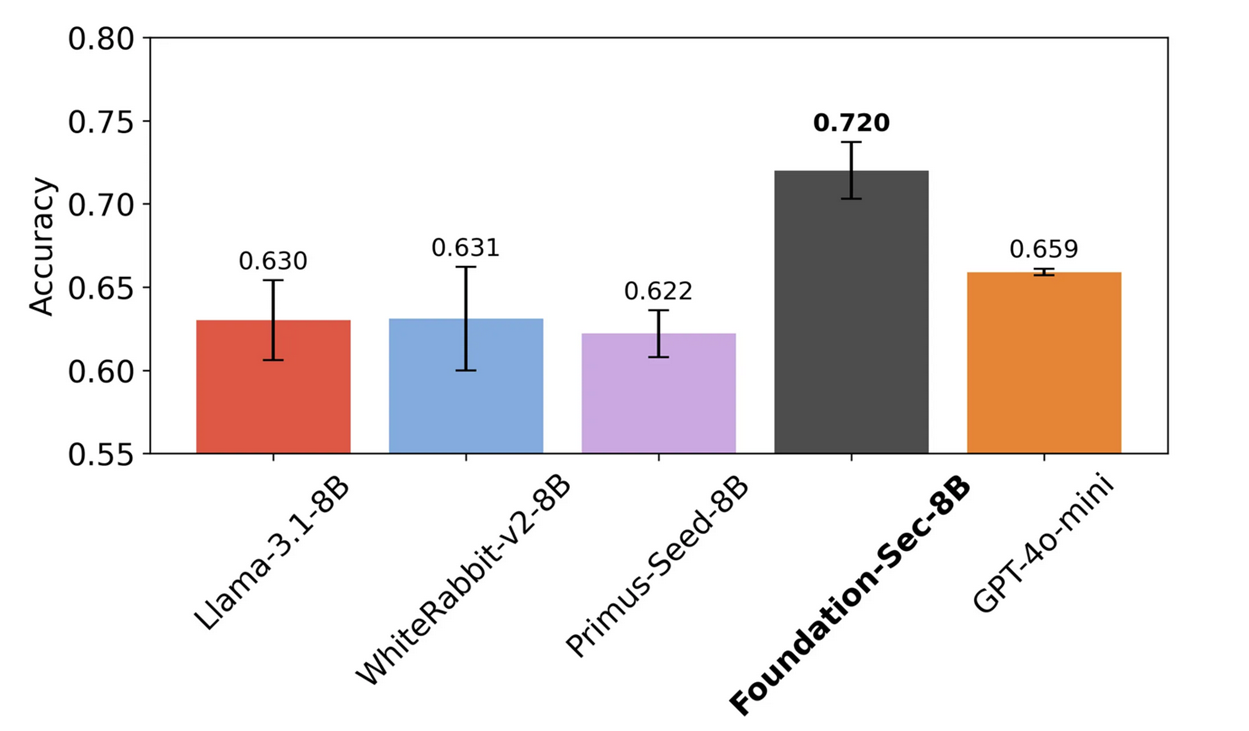
Comparison of models on the CTIBench-RCM benchmark over 10 trials
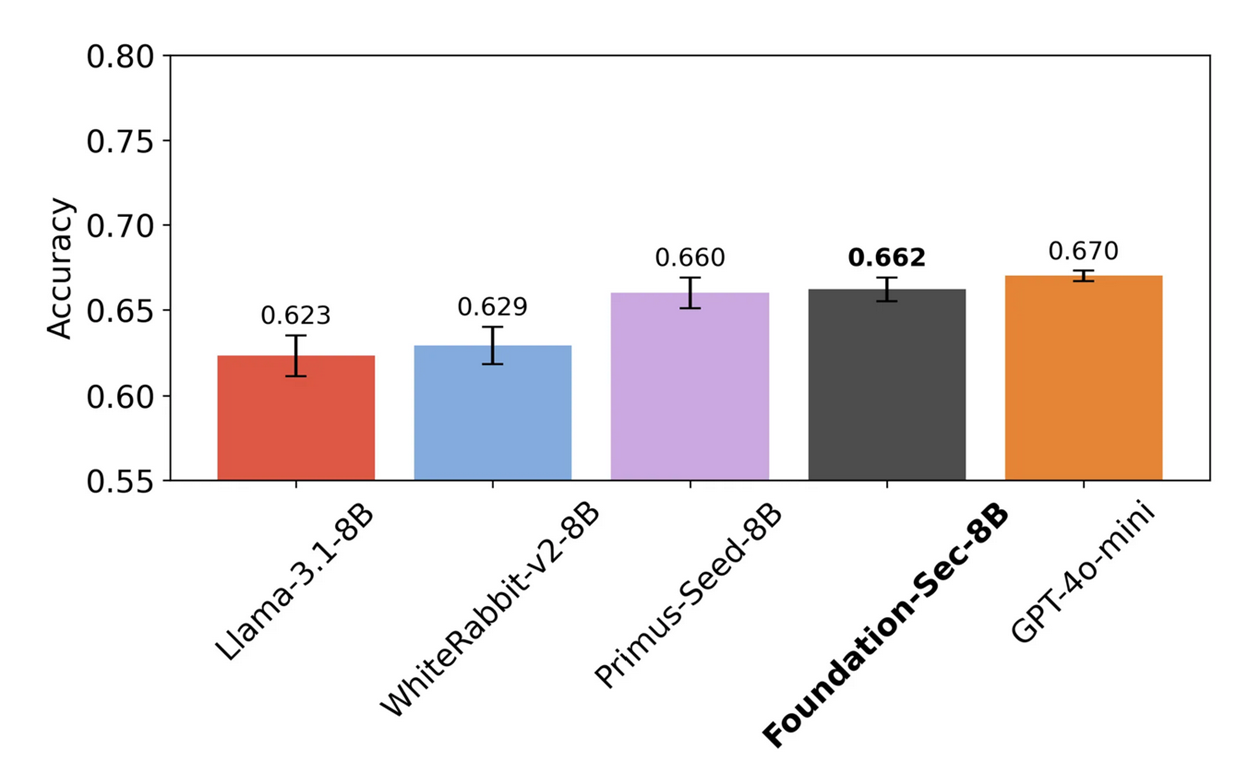
Comparison of models on the CTIBench-MCQA benchmark over 10 trials
Why Open Source?
Open-sourcing this package is our way of fostering collaboration and accelerating innovation at the intersection of cybersecurity and AI. Whether you're a researcher designing new benchmarks, a practitioner assessing cutting-edge LLMs, or a developer building AI-powered security tools, this package offers a flexible and reliable foundation to support your efforts.
How to Get Started
The FAITH Evaluation Package will officially launch at the end of July — stay tuned!
- Clone the repository from GitHub and set it up locally.
- Follow detailed documentation to configure and run benchmarks with ease.
- Contribute to the project by adding new benchmarks, refining existing ones, or extending core functionality.
Looking Ahead
We’re continually working to expand the package’s capabilities and benchmark coverage. Future updates will include:
- Additional cybersecurity-specific benchmarks
- Enhanced support for emerging LLM architectures, ensuring compatibility with the latest models
- Advanced evaluation metrics tailored to real-world security challenges
We can’t wait to see how the community builds on this foundation to push the boundaries of AI in cybersecurity.
If you have questions, feedback, or ideas for collaboration, we’d love to hear from you. Feel free to reach out or leave a comment below. Let’s work together to make cybersecurity AI evaluation easier, more reliable, and more impactful!
For more information on the Foundation AI team, check out our website. And to explore the foundation model we already released, Foundation-sec-8b is available for download on Hugging Face.
Contributors: Blaine Nelson, Baturay Saglam, Massimo Aufiero, Fraser Burch, Amin Karbasi, Paul Kassianik, Aman Priyanshu, Anu Vellore, Sajana Weerawardhena — thank you for helping bring FAITH to life.